
JavaScript Engine and the Event Loop


The JavaScript engine is a component present in every major web browser, that compiles and executes JavaScript source code, handles memory allocation of objects, and garbage collects objects no longer needed. The way it works is one of the most important differences from desktop runtime environments, as the JavaScript concurrency model handles multiple requests coming at the same time using an event loop on a single thread of execution, a model remarkably different from the Java Runtime Environment for example, that uses multiple execution threads.
On the other hand, parallelism takes the operations and assigns each one to a different CPU unit or core, so they run in a separate thread or process, so each operation makes progress at the same time.
The JavaScript Engine uses the concurrency model, as it is more predictable, easy to implement, and reasons about when we need to debug our code.
Article series
- The evolution of Frontend Development
- The rise of Single Page Applications
- What Front-end development really means?
- JavaScript Engine and the Event Loop
- JavaScript Programming Paradigms
Even when we don't interact with the JavaScript Engine and its concurrency model directly, understanding how it works is useful to avoid some wrong assumptions, especially regarding concurrent operations, as virtually every application handles asynchronous tasks like ajax calls, make use of the event loop. That is the case of the Dog Breed app presented in the first chapter and displayed again here in figure 1. This application has distinctive elements used to select a breed from a dropdown list, that in response makes an HTTP request to fetch a list of pictures corresponding to that dog breed.

When the user selects a dog breed and gets a list of gorgeous pictures of dogs from the breed, a series of steps happens under the hood by the JavaScript engine, which is known as the runtime model.
Runtime model
The code in the snippet below shows the functions called in the interaction of the user with the Dog Breed application (figure 1). First the user selects a breed from the dropdown button, that fires the `onSelectBreed(breed)` listener, so this function call is added into the stack, as shown in figure 2. This select listener then calls another function, `fetchBreedImages(breed)` to make an API call to get the list of pictures for the breed selected, from the remote API, which is handled as an asynchronous operation by the event loop, that we'll discuss shortly in the next subsection.
const BREED_URLS = {
list: () => "https://dog.ceo/api/breeds/list/all",
byBreed: (breed) => `https://dog.ceo/api/breed/${breed}/images`,
};
<1>
function onSelectBreed(breed) {
const button = document.querySelector("#dd-button");
button.innerText = breed;
fetchBreedImages(breed);
}
<2>
function fetchBreedImages(breed) {
const wrapper = document.getElementById("picture-wrapper");
wrapper.innerHTML = null;
fetch(BREED_URLS.byBreed(breed)).then((res) => res.json()).then(appendBreedPicture(wrapper));
}
<3>
function appendBreedPicture(wrapper) {
return (data) =>
Object.values(data.message)
.slice(0, 10)
.forEach((url) => {
const img = document.createElement("IMG");
img.src = url;
wrapper.appendChild(img);
});
}<1> Listener function that fires when the user selects a breed from the dropdown list.
<2> This function fetched the remote API to get the list of pictures for the selected breed.
<3> Appends the list of pictures to the wrapper element to build a mosaic of pictures, as illustrated in figure 1.
Thus, the stack creates what is known as a frame for every function call, used for the return address and parameters among other things. Also, as its name suggests, this memory area works a stack data structure, in which the first element to come in is the first to come out (First In, First Out, or FIFO), providing the ability to make nested calls to functions inside other functions.

On the other hand, there is also a Heap, which is a space of mostly unstructured memory, ta makes dynamic memory allocation for different kinds of objects.
The Heap and the Stack are concepts very similar to the model for other run-time environments like desktop or embedded systems. What tells apart the JavaScript engine is the use of a Queue, which is a list of messages with an associated function that gets called to handle the message. As the name suggests, the messages are handled by the run-time from the oldest one, so a message is removed from the queue and its callback function is called with the message as the input parameter, creating, in turn, a new stack frame for the callback function's use.
In our breed application, every new object generated by the call to fetch() that comes as the response from the remote API, resides in the Heap. As soon as the fetch function returns the reference to the response, the application code processes it and no other part of the code needs further access, the JavaScript engine then marks the object for garbage collection and the system claims back the memory space.
There is still another component in the runtime environment, called the Queue, which tells apart a browser's runtime environment from other run-times, as it's key to achieve concurrency with the Event Loop as we'll see shortly. The Queue as its name points out, is a space where callbacks functions are registered in the order of the last to come in is the first to come out (Last In, First Out or LIFO), as depicted in the bottom of figure 2. These callbacks are the functions called in response to asynchronous operations like click events or ajax calls, that are orchestrated by the Event Loop.
Event Loop
The event loop is not part of the JavaScript Engine, however, but a component in the browser runtime that is constantly awaiting asynchronously for the next message to come into the queue at some point, using a single thread of execution, as exemplified in the diagram of figure 3.
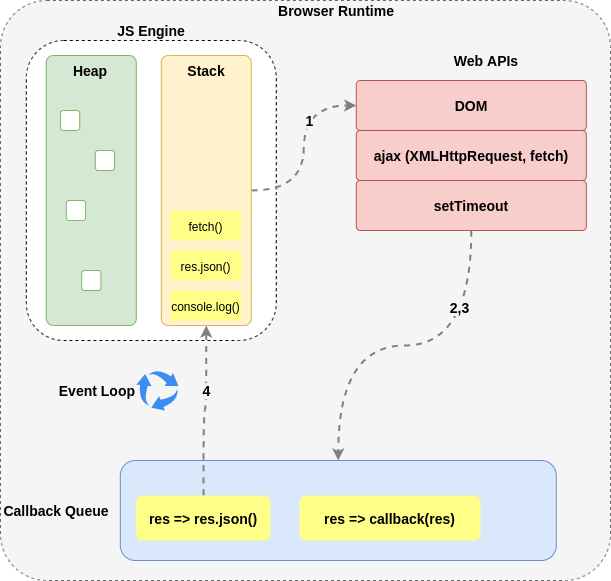
Let's imagine how the process of making an HTTP request happens internally in the browser run-time via the Event Loop using the previous code example, looking closer at what happens when the application fetches the remote API to get the list of pictures for the breed selected, a process made by the following code snippet,
function appendBreedPicture(wrapper) { <4>
return (data) =>
Object.values(data.message)
.slice(0, 10)
.forEach((url) => {
const img = document.createElement("IMG");
img.src = url;
wrapper.appendChild(img);
});
}
fetch(BREED_URLS.byBreed(breed)) <1>
.then((res) => res.json()) <2>
.then(appendBreedPicture(wrapper)); <3><1> Call Web API to fetch data
<2> When request's done, parse result
<3> Then execute callback function<4> Callback function prints the result
When the fetch request is complete and returns a result, a callback parses it into JSON (2), and immediately after, another callback appends the images into a wrapper (HMTL) element (3). This process is followed in the same order in figure 3. Notice the first request to fetch (1) is an asynchronous operation, meaning that we don't know when is going to be completed, or even if it's going to succeed and return something.
Synchronous vs Asynchronous
When we talk to an asynchronous process, in general terms, we talk to refer to a process that invokes another process and waits for a response, in a timely fashion, as depicted in figure 4. For example, if we call a function that performs an arithmetic operation like a sum, we expect that the function returns an integer, and the execution flow of our code pauses to wait for the response before it continues with the next statement. In the case of regular code execution in a programming language, the time waiting time is very short (milliseconds or less) so it feels immediate, but it doesn't need to be the case, it could be any given amount of waiting time.
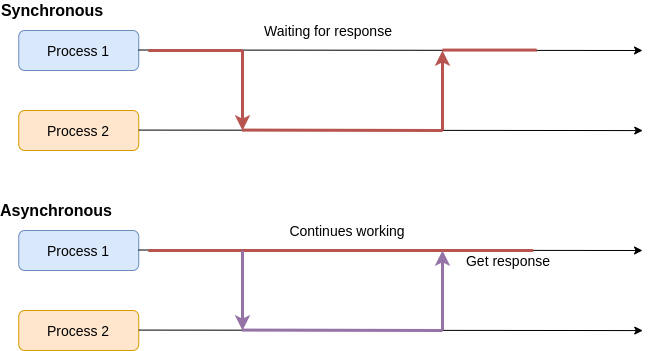
On the other hand, an asynchronous process doesn't wait for a response from an invocation to another process, it just continues its normal operation (figure 4), and when a response arrives (if any) from the invocation, then it does something with it. In the case of the JavaScript runtime, it is, of course, calling a callback function.
An important characteristic of the asynchronous process is that, as it doesn't wait for any response from calls to another process, then the order of the responses is not necessarily the same as the calls. For example, in figure 5, _process 1_ makes a call to _process 2_ and after that, another call to _process 3_. If _process 1_ was synchronous, then it would wait for the first response to arrive and then make the second call, having the responses in the same order, but in this case, as _process 3_ has a smaller time to complete than _process 2_, then it arrives first, even when it was called at later point of time.

Asynchronous processes are essential for web applications because they allow the application to make ajax requests and continue working to let the user do other tasks, without blocking the application with waiting times. Imagine if the user of the Dog Breed application should wait every time it selects a breed and the response from the pictures, it would feel as the application freezes temporarily while loading the images, not allowing the easily changing the user's mind to select a different breed. Nevertheless, the Dog Breeds app is a very simple application with a single interaction, but with complex applications, having multiple ajax calls at the same time, like in a social media app, asynchronous processes become critical. Having a good understanding of how asynchronous jobs work will allow us to understand some powerful patterns and tools, like Reactive Extensions and the Redux pattern, used for simplifying the handling of the application state with multiple concurrent processes. We'll come back to these interesting topics and future articles.
Thus, HTTP is a synchronous protocol, but the JavaScript runtime runs an asynchronous process.
Web APIs
Web APIs are an extensive collection of application programming interfaces (APIs) available to some extent in terms of compatibility in every major web browser. They allow us to perform many low-level and granular tasks in our runtime environment. We have already seen one of the most used Web APIs in web development, the DOM API. These APIs provide built-in functionalities to perform various tasks and are the building blocks for many JavaScript libraries and frameworks. We can cite some of the APIs most commonly used:
- Console API: It provides functionality to perform debugging tasks, such as logging messages or the values of variables at set points in our code.
- HTML Drag and Drop API: Enables applications to use drag-and-drop features in web browsers.
- Geolocalization API: It allows the users to provide their location to the application if they want it to do so (permission asked).
- History API: The DOM Window object part provides access to the browser’s history.
- Service Workers API: It facilitates running an operation in a background thread separate from the main execution thread of the application.
- Websockets API: It provides the means to open a two-way real-time communication session between a browser and a web server.
- XMLHttpRequest: Also known as XHR, it is an object used to communicate with web servers, commonly used in AJAX programming.
One important thing to remark about Web APIs is the fact that they are the base toolset for development libraries to implement all of their functionality. Libraries and frameworks are merely an abstraction layer over these Web APIs. Even when an abstraction layer in the way of a framework provides more complex and richer functionality, hiding implementation details, it doesn't have everything we need to all use cases, so we'd need to design our feature using the Web APIs directly, thus, mastering them presents an advantage for solving customized components and features.
In the next post, we'll analyze the JavaScript programming language and its multiparadigm feature for FrontEnd Architecture.